前置き
最近今更ながらポケモンカードに興味を持ちました。
トレーディングカードにはカードの状態を第三者機関が鑑定する「PSA鑑定」というものがあり興味を持ったため少し調べてみました。
トレーディングカードのPSAとは
PSA(Professional Sports Authenticator)は、トレーディングカードやスポーツ記念品などの認証と評価を行うアメリカの企業です。PSA鑑定は、カードの真正性、状態を専門的に評価し、等級を付けるプロセスです。この等級は1から10まであり、数値が高いほどカードの状態が良いことを意味します。
PSA鑑定の注意点
- コストと時間: PSA鑑定は有料で、鑑定には数週間から数ヶ月かかることがあります。コストと時間を考慮して、鑑定に出すカードを選ぶ必要があります。
- 鑑定の基準: PSAは厳格な基準でカードを評価します。カードの状態に自信がない場合は、低い評価を受けるリスクがあります。
- 偽物の警戒: 偽のPSA鑑定カードが市場に出回ることがあるため、購入時は正規の認証マークを確認することが重要です。
PSA鑑定情報のスクレイピング方法
PSA鑑定情報を収集するためのスクレイピングは、自動化ツールを用いてウェブサイトから情報を抽出するプロセスです。Pythonの「Beautiful Soup」や「Scrapy」といったライブラリを使用すると効率的にデータを収集できます。
スクレイピングの注意点
- 法的制約: ウェブサイトには著作権があり、無断でのデータ収集は法的問題を引き起こす可能性があります。スクレイピングする前に、対象サイトの利用規約を確認しましょう。
- サーバーへの負荷: 頻繁なアクセスはウェブサイトのサーバーに負荷をかけ、場合によってはアクセス遮断の原因となり得ます。スクレイピングは適切な間隔を空けて行うことが大切です。
- データの正確性: スクレイピングで得られるデータは常に最新のものとは限らず、時に誤った情報を含むことがあります。収集したデータは必ず確認し、可能な限り他の情報源と照らし合わせて検証しましょう。
サンプルコード
サンプルコードをいくつか作成してみました。
- カード単位の情報取得
- カードごとに集約した情報の取得
- カードシリーズごとに集約した情報の取得
1.カード単位の情報取得
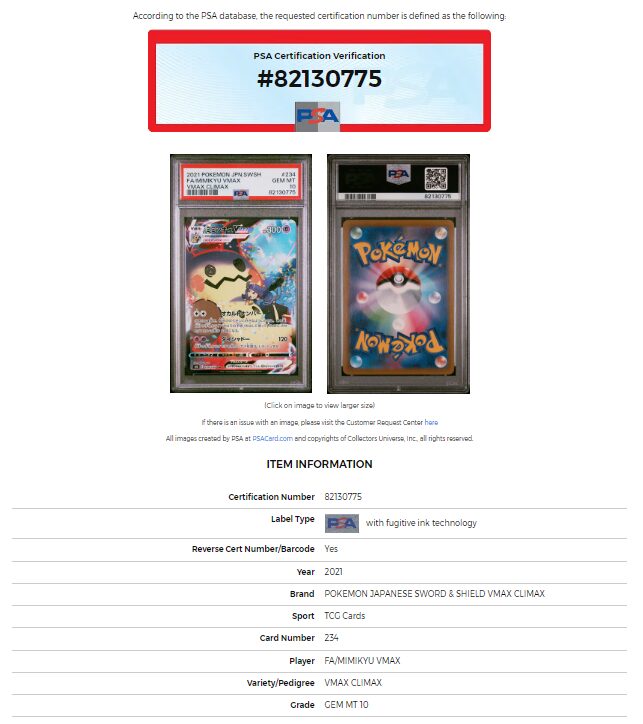
下記のページの情報を取得するためのサンプルコードです。※このカードは私が所持しているものです。
https://www.psacard.com/cert/82130775
import requests
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
import os
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def scrape_psa_cert(cert_number):
try:
url = f"https://www.psacard.com/cert/{cert_number}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 各項目を安全に抽出
def safe_find(tag, string):
found = soup.find(tag, string=string)
return found.find_next_sibling('td').text if found else None
return {
'Certification Number': cert_number,
'Label Type': safe_find('th', 'Label Type'),
'Reverse Cert Number/Barcode': safe_find('th', 'Reverse Cert Number/Barcode'),
'Year': safe_find('th', 'Year'),
'Brand': safe_find('th', 'Brand'),
'Sport': safe_find('th', 'Sport'),
'Card Number': safe_find('th', 'Card Number'),
'Player': safe_find('th', 'Player'),
'Variety/Pedigree': safe_find('th', 'Variety/Pedigree'),
'Grade': safe_find('th', 'Grade')
}
except Exception as e:
print(f"Error scraping cert {cert_number}: {e}")
return None
def scrape_range(start_cert, end_cert):
data = []
with ThreadPoolExecutor(max_workers=5) as executor:
future_to_cert = {executor.submit(scrape_psa_cert, cert_number): cert_number for cert_number in range(start_cert, end_cert + 1)}
for future in tqdm(as_completed(future_to_cert), total=end_cert - start_cert + 1):
item_info = future.result()
if item_info:
data.append(item_info)
time.sleep(10) # 各イテレーションの間に10秒待機
return pd.DataFrame(data)
# 開始番号と終了番号を設定
start_cert_number = 80000001 # 例
end_cert_number = 80000010 # 例
# スクレイピング実行
df = scrape_range(start_cert_number, end_cert_number)
df出力結果
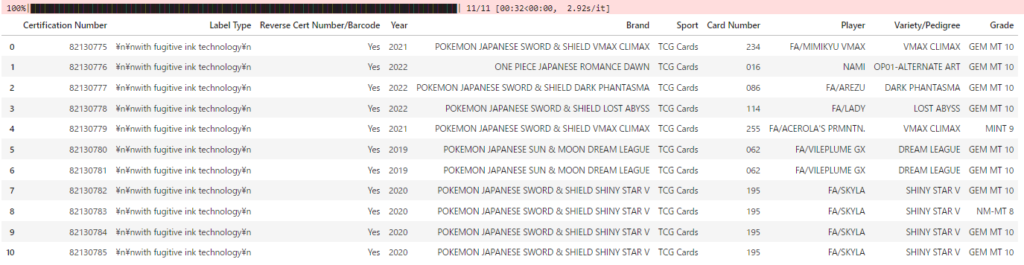
問題点
現在PSA鑑定されているカード数は8,000万以上となり、サーバーに負荷をかけないような頻度で情報を取得する場合、情報を得るまでに数年単位の時間が必要となるため現実的ではない。
2.カードごとに集約した情報の取得
下記のページの情報を取得するためのサンプルコードです。
https://www.psacard.com/pop/tcg-cards/2023/pokemon-japanese-sv4a-shiny-treasure-ex/255404
このページはJavaScriptが使用されているため selenium ライブラリを使用します。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
import pandas as pd
import time
def scrape_psa_data(url):
# ChromeDriverのパスを指定してServiceオブジェクトを作成
path_to_chromedriver = 'C:\\chromedriver.exe' # パスは適宜修正してください
service = Service(executable_path=path_to_chromedriver)
driver = webdriver.Chrome(service=service)
# URLにアクセス
driver.get(url)
# JavaScriptがロードされるのを待つ
time.sleep(5)
# BeautifulSoupでページの内容を解析
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()
# シリーズ名を取得
series = soup.find('ul', class_='breadcrumb-list').find_all('li')[-1].text.strip()
# 以下はBeautifulSoupを使用したスクレイピングの処理
table = soup.find('table')
rows = table.find_all('tr')
columns = ['index', 'CARD NO.', 'NAME', 'Rarity', 'grade', 'AUTH', '1', '1.5', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'TOTAL']
data = []
for row in rows[1:]:
cols = row.find_all('td')
row_data = []
for i, col in enumerate(cols):
if i == 2: # NAME列
divs = col.find_all('div')
name = divs[0].text.strip() if divs else col.text.strip()
name = name.replace("Shop with Affiliates", "").strip()
rarity = divs[1].text.strip() if len(divs) > 1 else ""
row_data.append(name)
row_data.append(rarity)
else:
first_div = col.find('div')
text = first_div.text.strip() if first_div else col.text.strip()
text = text if text != "–" else "0"
row_data.append(text)
if row_data:
data.append(row_data)
df = pd.DataFrame(data, columns=columns)
# '10rate'列を計算
df['10'] = pd.to_numeric(df['10'])
df['TOTAL'] = pd.to_numeric(df['TOTAL'])
df['PSA10取得率'] = df['10'] / df['TOTAL']
df['PSA10取得率'] = df['PSA10取得率'].round(3) # 小数点第三位まで表示
# シリーズ名をDataFrameに追加し、不要な列を削除
df.insert(0, 'Series', series)
df.drop(['index', 'grade'], axis=1, inplace=True)
return df
# URL
url = "https://www.psacard.com/pop/tcg-cards/2023/pokemon-japanese-sv4a-shiny-treasure-ex/255404"
# スクレイピング実行
df = scrape_psa_data(url)
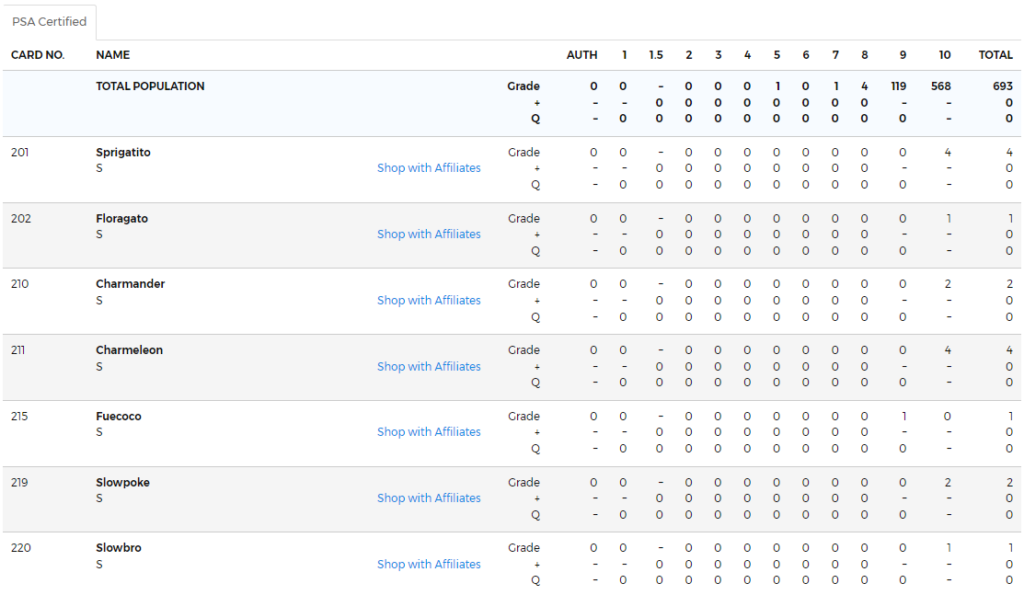
df問題点
レアリティがポケモン名に連結されてしまっている。
出力結果
PSA10取得率についてはURLに含まれていませんが計算しています。
3.カードシリーズごとに集約した情報の取得
下記のページの情報を取得するためのサンプルコードです。
https://www.psacard.com/pop/tcg-cards/2023/227655
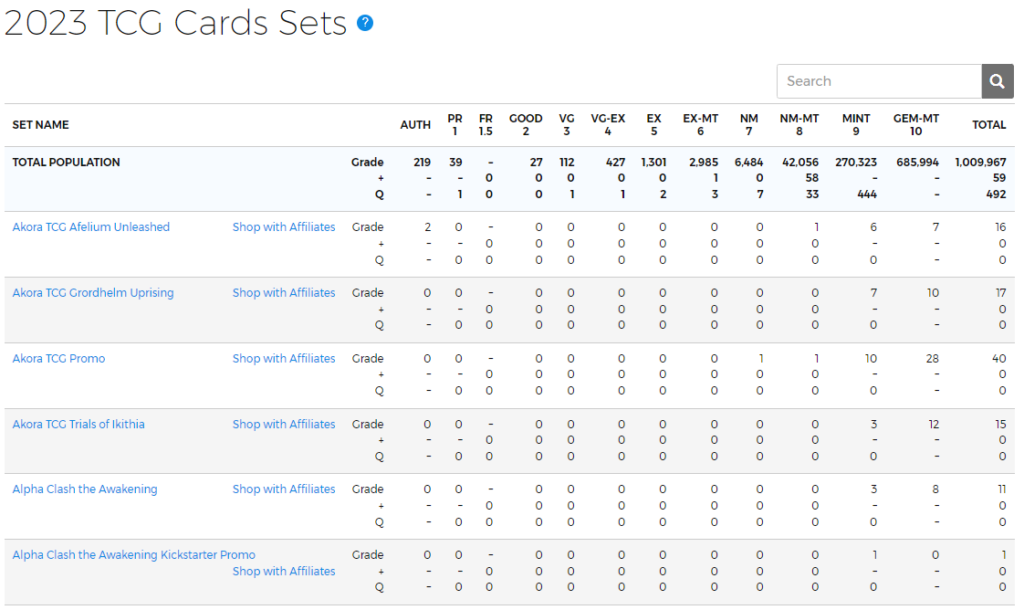
import requests
from bs4 import BeautifulSoup
import pandas as pd
def scrape_psa_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 年を抽出
year = soup.find('ul', class_='breadcrumb-list').find_all('li')[-1].text.strip()
# テーブルのデータを抽出
table = soup.find('table')
rows = table.find_all('tr')
# 列名のリスト
columns = ['index', 'SET_NAME', 'grade', 'AUTH', '1', '1.5', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'TOTAL']
# データを格納するリスト
data = []
# 各行のデータを抽出
for row in rows[1:]: # 最初の行はヘッダーなのでスキップ
cols = row.find_all('td')
row_data = []
for i, col in enumerate(cols):
text = col.text.strip()
if i == 1: # 'SET NAME'列
text = text.replace("Shop with Affiliates", "").strip()
elif i > 2: # 'AUTH'列以降
text = text.split('\n')[0]
text = text.replace(",", "") # カンマを削除
text = text if text != "-" else "0" # "-" を "0" に置換
row_data.append(text)
row_data = [year] + row_data # 年を最初に追加
if row_data:
data.append(row_data)
# DataFrameを作成
df = pd.DataFrame(data, columns=['Year'] + columns)
# 不要な列を削除
df.drop(['index', 'grade'], axis=1, inplace=True)
# '10rate'列を計算
df['10'] = pd.to_numeric(df['10'])
df['TOTAL'] = pd.to_numeric(df['TOTAL'])
df['10rate'] = df['10'] / df['TOTAL']
df['10rate'] = df['10rate'].round(3) # 小数点第三位まで表示
return df
# URL
url = "https://www.psacard.com/pop/tcg-cards/2023/227655"
# スクレイピング実行
df = scrape_psa_data(url)
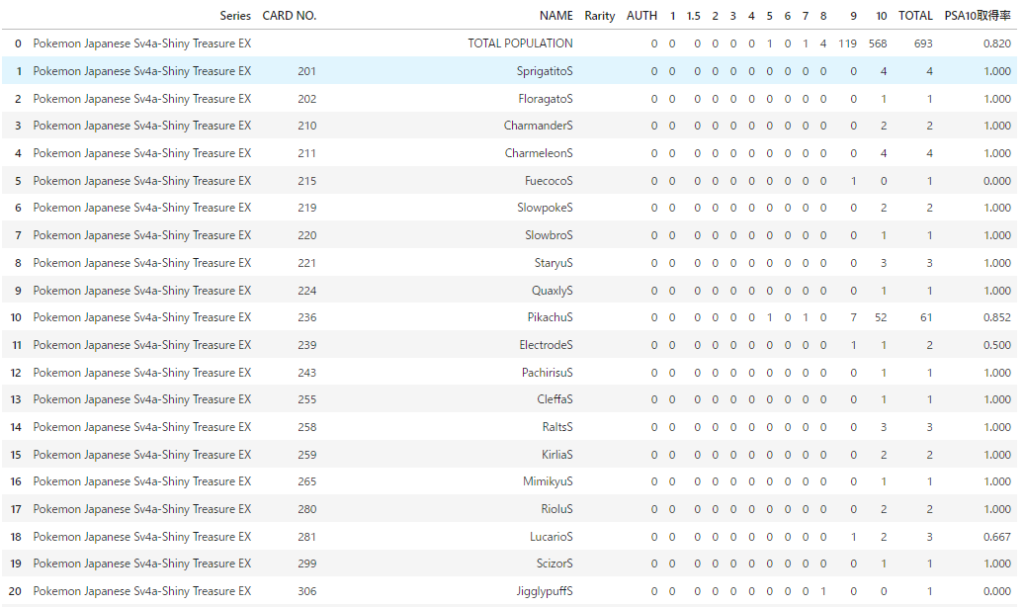
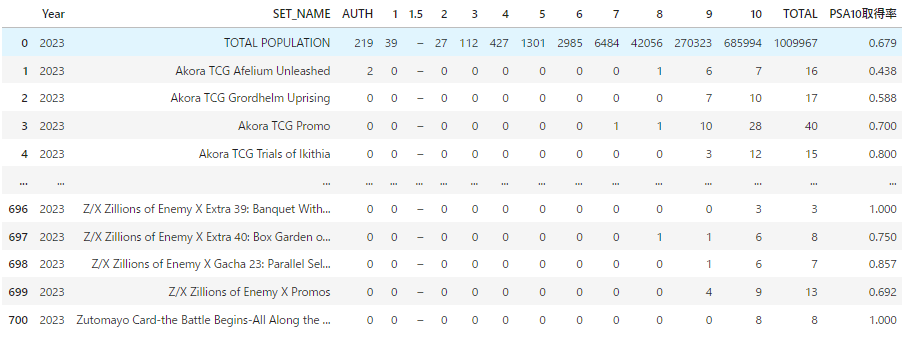
df出力結果
PSA10取得率についてはURLに含まれていませんが計算しています。
まとめ
PSA鑑定はトレーディングカードの価値を決定する重要な要素ですが、鑑定にはコストと時間がかかるため、慎重に検討する必要があります。また、PSA鑑定情報のスクレイピングは有用な手段ですが、法的な問題やサーバーへの負荷、データの正確性に注意することが重要です。
この記事がトレーディングカードのコレクターや投資家の皆さんにとって有益な情報源となることを願っています。